- Linux
- 21 juillet 2017 à 12:23
-

- 1/2

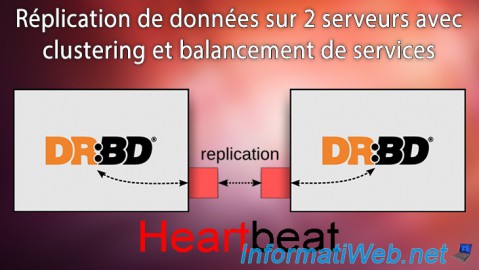
Lorsque l'on héberge des données sur un serveur et/ou que l'on propose des services hébergés sur un ou plusieurs serveurs, il est important que ces données et/ou services puissent être disponibles, et ce même en cas de plantage d'un serveur.
Pour éviter que le service ou les données importantes ne deviennent inaccessibles, on met souvent en place de la haute disponibilité.
Dans le cas d'un serveur sous Linux, nous pouvons fournir de la haute disponibilité pour quasiment n'importe quel service (web, FTP, NFS, iSCSI, ...) grâce à DRBD et Heartbeat.
Notez que Heartbeat est limité à 2 serveurs. Pour créer un cluster de plus de 2 serveurs, vous devrez utiliser Pacemaker.
Mais, gardez à l'esprit que Heartbeat est très utilisé pour ses performances, sa souplesse et sa stabilité.
- Qu'est-ce que DRBD
- Qu'est-ce que Heartbeat
- Configuration utilisée
- DRBD (Réplication des données)
- Heartbeat (Cluster et balancement de services)
- Test du cluster
1. Qu'est-ce que DRBD
DRBD signifie Distributed Replicated Block Device et permet de créer une sorte de RAID 1 via le réseau.
C'est donc DRBD qui nous permettra de créer une copie en temps réel d'un disque dur, d'une partition ou d'un système LVM, sur un autre serveur.
Cette synchronisation sera effectuée en temps réel via le réseau et c'est la raison pour laquelle il est recommandé (mais pas obligatoire) d'utiliser un réseau dédié entre les 2 serveurs concernés (le serveur principal et celui de secours).
Grâce à DRBD, nos données seront accessibles depuis 2 serveurs. Si un serveur est défaillant, les données seront toujours accessibles depuis l'autre serveur.
Néanmoins, il manque quelque chose pour que le service soit toujours accessible par vos utilisateurs.
C'est ce que nous allons voir à l'étape suivante. (Heartbeat)
2. Qu'est-ce que Heartbeat
Heartbeat est un programme qui permet de surveiller la disponibilité d'un serveur et lorsque l'un d'entre eux est défaillant, les services sont automatiquement basculés sur l'autre serveur.
Pour effectuer cette vérification, les 2 serveurs se contacteront via le réseau à intervalle régulier.
En résumé, si le serveur 1 est défaillant, l'utilisateur pourra toujours accéder aux mêmes services via le serveur 2.
De plus, pour que cela soit transparent pour vos utilisateurs, vous devrez définir une adresse IP virtuelle via Heartbeat.
Pour finir, sachez qu'il fortement recommandé d'utiliser au moins 2 chemins différents pour vérifier qu'un autre serveur est toujours disponible.
Cela permet d'être sûr que le serveur est défaillant.
En effet, si une carte réseau est défaillante, heartbeat connaitra toujours l'état du serveur via l'autre
carte réseau. Dans le cas contraire, Heartbeat aurait considéré à tort que l'autre serveur était défaillant.
3. Configuration utilisée
2 serveurs Debian 7.7.0 x64 avec :
- 2 disques durs chacun (1 pour Debian et l'autre pour les données à répliquer)
- 2 cartes réseaux chacun (1 pour l'accès depuis l'extérieur et l'autre dédiée à la réplication des données)
Comme indiqué précédemment, l'utilisation de 2 cartes réseau permettra d'avoir :
- une carte réseau pour l'accès depuis l'extérieur effectué par vos utilisateurs
- un réseau dédié pour la réplication des données. La réplication sera donc plus rapide et n'affectera pas les performances réseau pour les accès utilisateurs.
Pour relier vos 2 serveurs entre eux, vous pouvez utiliser un routeur, un switch ou même un câble croisé (branché directement sur les 2 cartes réseau eth1 (voir ci-dessous) de chacun de vos serveurs).
Dans notre cas, ces 2 serveurs auront donc 2 interfaces réseau :
- eth0 : 10.0.0.31 pour le serveur 1 et 10.0.0.32 pour le serveur 2. Il s'agit de la carte réseau connectée au routeur via lequel les utilisateurs accéderont à nos services (serveur web, ...)
- eth1 : 192.168.1.31 pour le serveur 1 et 192.168.1.32 pour le serveur 2. Il s'agit de la carte réseau connectée sur un autre routeur ou sur un switch (étant donné que les serveurs auront des IP fixes, le serveur DHCP sera inutile dans ce cas-ci)
Pour définir les adresses IP sur vos serveurs Linux, référez-vous à nos tutoriels : Debian - Définir une adresse IP privée statique ou Ubuntu - Définir une adresse IP privée statique.
Note : si vous ne possédez pas de passerelle pour l'interface eth1, il suffit de ne pas indiquer la ligne "gateway" pour cette interface dans le fichier "/etc/network/interfaces".
Dans notre cas, nous avons donc un réseau dédié entre nos 2 serveurs via le switch et les interfaces eth1 de nos 2 serveurs.
4. DRBD (Réplication des données)
IMPORTANT : les commandes indiquées devront toujours être exécutées sur vos 2 serveurs (sauf mention contraire), et ce simultanément (sinon, vous risque d'obtenir des messages d'erreur).
4.1. Installation
Avant de commencer, nous allons créer une partition sur le 2ème disque dur (sdb) de chaque serveur.
Pour cela, tapez ceci sur les 2 serveurs :
Bash
fdisk /dev/sdb
Pour créer une partition sur tout le disque dur, tapez "n" (nouvelle partition), puis "p" (primaire), puis laissez les valeurs par défaut pour le reste.
Lorsqu'il vous demande à nouveau une commande, tapez "w" (écrire la table de partitions).
Si vous souhaitez partitionner votre disque dur autrement, référez-vous à notre tutoriel : Partitionner son disque dur avec fdisk
Pour installer DRBD, il suffit d'installer le paquet "drbd8-utils" sur les 2 serveurs.
Bash
apt-get install drbd8-utils
Une fois installé, activez le module "drbd".
Bash
modprobe drbd
Note : pour obtenir des infos concernant la version de DRBD, utilisez cette commande :
Bash
modinfo drbd
4.2. Configuration des ressources
Comme indiqué dans la documentation officielle, les ressources doivent être définies dans des fichiers "*.res".
Dans notre cas, nous allons donc créer un fichier "drbd0.res".
Note : ce fichier doit être identique sur les 2 serveurs.
Bash
vi /etc/drbd.d/drbd0.res
Dans ce nouveau fichier, nous allons coller ceci.
Notez que :
- iw0 est le nom de la ressource dont on aura besoin plus tard pour gérer cette ressource.
- server1 et server2 correspondent aux noms (hostname) de nos 2 serveurs Debian.
- 192.168.1.31 et 192.168.1.32 correspondent aux adresses IP de nos 2 serveurs Debian sur le réseau dédié (le switch).
- "device /dev/drbd0" correspond au "disque" fourni par DRBD
- "disk /dev/sdb1;" la partition 1 (sdb1) de notre disque dur "sdb".
- "syncer" permet de limiter la vitesse de synchronisation entre les 2 serveurs. (facultatif)
Plain Text
resource iw0 {
startup {
wfc-timeout 30;
degr-wfc-timeout 15;
}
disk {
on-io-error detach;
}
# Taux de transfert
# 10M pour du 100mbits
# 100M pour du 1Gbits
syncer {
rate 100M;
}
on server1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.31:7788;
meta-disk internal;
}
on server2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.32:7788;
meta-disk internal;
}
}
Sur les 2 serveurs, vérifiez et modifiez si nécessaire le nom de votre serveur en modifiant les fichiers :
- "/etc/hostname" : contient uniquement le nom de votre serveur Linux
- "/etc/hosts" : contient les correspondances entre le nom de votre serveur Linux et son adresse IP.
Bash
vi /etc/hostname
Note : si vous modifiez le nom de votre serveur Linux, il est préférable de le redémarrer complètement.
Pour éviter les problèmes, ajoutez ceci dans le fichier "/etc/hosts" de vos 2 serveurs.
Bash
vi /etc/hosts
Plain Text
192.168.1.31 server1 192.168.1.32 server2
4.3. Activation de la réplication des données
Pour activer la réplication des données, utiliser ces commandes.
Note : iw0 correspond au nom de la ressource que nous venons de définir dans le fichier "drbd0.res".
Bash
drbdadm create-md iw0 drbdadm up iw0
Si vous utilisez la commande "drbd-overview", vous devriez voir que vos 2 serveurs sont actuellement connectés et qu'ils sont tous les 2 en "secondaire".
Du coup, la réplication ne s'effectue pas étant donné que DRBD ne sait pas dans quel sens il doit synchroniser les données.
Bash
drbd-overview
Plain Text
0:iw0 Connected Secondary/Secondary Inconsistent/Inconsistent C r-----
Pour régler le problème, tapez cette commande sur le serveur 1 (uniquement) :
Bash
drbdadm -- --overwrite-data-of-peer primary iw0
Maintenant, DRBD sait que le serveur 1 est le serveur principal et que l'autre est le serveur secondaire (celui qui sera utilisé en cas de défaillance du serveur principal).
Note : si vous avez besoin de repasser le serveur maitre en secondaire, voici la commande à utiliser :
Bash
drbdadm secondary r0
Si vous tapez la commande "drbd-overview", vous verrez que DRBD commence la réplication des données du serveur principal (Primary) vers le serveur secondaire (Secondary).
Ceci peut prendre du temps en fonction de l'utilisation de votre réseau et de la taille du "disque" à répliquer.
Bash
drbd-overview
Plain Text
0:iw0 SyncSource Primary/Secondary UpToDate/Inconsistent C r----- [>....................] sync'ed: 0.2% (81760/81916)Mfinish: 0:08:53 speed: 156,416 (156,416) K/sec
Pour vérifier l'état de la synchronisation, vous pouvez aussi utiliser la commande :
Bash
cat /proc/drbd
Ou cette commande pour voir l'avancement en live.
Note : appuyez sur CTRL + C pour quitter le programme "watch".
Bash
watch cat /proc/drbd
4.4. Création du système de fichier sur le disque de DRBD
Pour pouvoir stocker des données sur la partition répliquée par DRBD, vous devrez y créer un système de fichiers.
Pour cela, utilisez la commande :
Bash
mkfs.ext4 /dev/drbd0
Si vous recevez cette erreur, c'est que votre serveur principal n'est pas en "Primary" ou que vous tentez de créer le système de fichiers sur le disque
"/dev/drbd0" du serveur secondaire.
Bash
mke2fs 1.42.5 (29-Jul-2012) mkfs.ext4: Mauvais type de medium lors de la tentative de détermination de la taille du système de fichiers
Pour régler ce problème, tapez cette commande sur votre serveur principal.
Bash
drbdadm -- --overwrite-data-of-peer primary iw0
Maintenant, nos données seront toujours disponibles depuis 2 serveurs.
Il ne reste qu'à créer un cluster avec ces 2 serveurs pour que nos services soient accessibles via une IP unique et que les services soient toujours disponibles, même si un des 2 serveurs tombe en panne.
Partager ce tutoriel
A voir également
-

Linux 31/12/2016
Debian - Transformer son serveur en routeur et en serveur DHCP
-

Linux 12/3/2015
Debian / Ubuntu - Configurer un serveur et un client NFS
-

Linux 14/2/2015
Debian / Ubuntu - Créer une autorité de certification racine
-

Linux 26/12/2014
Debian / Ubuntu - Détecter les attaques grâce à Logwatch
Vous devez être connecté pour pouvoir poster un commentaire